Data als grondstof voor machine learning algoritmes
Met machine learning kan je processen verbeteren, klantbeleving optimaliseren en menselijke handelingen automatiseren. De grondstof voor machine learning is data. Data zit in de systemen van je organisatie, is online beschikbaar als open data of via betaalde diensten. Exploratieve data analyse is een aanpak om data te analyseren.
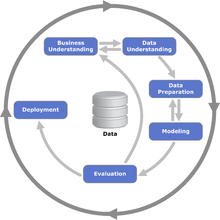
Data analyse en CRISP-DM
Data science projecten starten met het bepalen van de gewenste epics, features en globale user story’s. Deze processtap wordt in het CRISP-DM proces ‘Business understanding’ genoemd.
Daarna is het belangrijk om de data te leren kennen, de hypothese (aanname) over het voorspellende karakter van de data te onderzoeken en te bepalen welke bewerkingen nodig zijn om de data als grondstof voor machine learning te gebruiken.
Data analyse voer je uit in de CRISP-DM processtap ‘Data understanding’. De aanpak om de data te onderzoeken en de hypothese te toetsen noemen we exploratieve data analyse, afgekort EDA.
Exploratieve data analyse, afgekort met EDA, is een aanpak om data te onderzoeken op inhoudelijke kenmerken, samenhang, verklarende of voorspellende eigenschappen. We spreken ook wel van verkennende data analyse.
Naast inhoudelijke en technische kennis over de data zijn we opzoek antwoorden op vragen zoals:
- Kunnen we seizoensinvloeden ontdekken in de trend?
- Zijn onze processen vergelijkbaar qua gemiddelde doorlooptijd?
- Hoe sterk is de samenhang tussen weer en aantal bezette parkeerplaatsen?
- Welke variabelen (features) hebben het hebben de hoogste voorspellende (of verklarende) waarde?
Doel van exploratieve data analyse
Exploratieve data analyse als aanpak, afgekort EDA, werd al in 1977 beschreven door John W. Tukey en wordt nu in het data science vakgebied verder ontwikkeld. Het is een aanpak gebaseerd op eigen waarnemingen, die aan het einde van het proces worden bevestigd met statistische methoden.
Het doel van EDA is het kiezen van het eenvoudigste data model met de minste aannames, laagste aantal variabelen en het hoogste verklarende (of voorspellende) vermogen met de laagst mogelijke negatieve effecten binnen machine learning algoritmes zoals bias, hoge variatie of ‘overfitting’.
Verkennende data analyse wordt daarnaast ingezet binnen informatie gestuurd werken om vragen te beantwoorden over o.a. data kwaliteit, analyse van processen of voor ad-hoc management informatie.
Veel methoden zijn grafisch. Door gebruik te maken van data visualisaties worden verwachte of juist onverwachte eigenschappen intuïtief zichtbaar. De grafische methoden worden aangevuld met statische technieken om o.a. patronen of verbanden te herkennen en te bevestigen.
Wat doet de data analist?
Als data analist definieer je de meest optimale data set die als grondstof kan dienen voor het machine learning algoritme. Het onderzoek tijdens de exploratieve data analyse omvat o.a.:
- Een samenvatting van de data met behulp van beschrijvende statistiek. Dit is vaak de eerste stap en geeft een globaal beeld van het karakter van de data.
- Herkennen van fouten in de data, denk aan ontbrekende waardes of variabelen met een uitzonderlijk lage variatie.
- Onderzoek naar interessante patronen in de data, zoals trends, seizoensinvloeden, groeperingen (clusters) en afwijkingen hierop.
- Testen van de aannames die zijn gedaan over het voorspellende en/of verklarende vermogen van de data.
- Onderzoeken van de samenhang tussen de variabelen onderling en het gewenste resultaat.
- Identificeren van variabelen die de meeste invloed hebben op het gewenste resultaat.
- Noodzakelijke bewerkingen op de data voordat deze als grondstof gebruik kan worden voor machine learning. Aandachtspunten zijn o.a. ontbrekende waardes, normaliseren, outliers, lage variatie en het reduceren van dimensionaliteit.
Datavisualisatie, mijn favoriete grafieken voor data analyse
Tijdens EDA is datavisualisatie een belangrijke methode om patronen, kenmerken en samenhang in de dataset te herkennen. Door gebruik te maken van grafieken worden deze beter zichtbaar. Mijn favorieten zijn:
Histogrammen, frequentie verdeling en aanname van normaliteit
Histogrammen combineer je met een density curve om de aanname van normaliteit te toetsen. Deze combinatie visualiseert de frequentietabel en toont daarbij de density curve om een indruk te krijgen van de spreiding. Als er sprake is van asymmetrie, scheefheid (skewness) dan is dat aanleiding voor verder onderzoek. Een andere grafiek voor het toetsen op normaliteit is een Q-Q Plot.
Boxplot, outliers ontdekken
Een boxplot toont een vijf-getallen samenvatting van de frequentietabel. Deze grafiek geeft inzicht de spreiding van de variabele. De outliers (uitschieters) worden individueel getoont. Een boxplot toont het minimum, maximum, interkwartielafstand en is erg handig outliers (uitschietsers) in de data visueel te signaleren.
“The greatest value of a picture is when it forces us to notice what we never expected to see.”
John W. Tukey
Scatterplot, samenhang tussen twee variabelen
Een scatterplot gebruik je om de samenhang tussen twee variabelen te tonen en wordt daarom ook wel correlatiediagram genoemd. Een scatterplot toont de data punten uitgezet over de x-as (variabele 1) en en y-as (variabele 2). Eventueel kan je de punten kleuren door ze te koppelen aan een derde categorische variabele. Naast de samenhang wordt een eventuele groepering goed duidelijk. Bijvoorbeeld: woningprijs en woonoppervlakte, per woningtype.
Trendlijn: dalen, pieken en seizoensinvloeden
Een trendlijn kan naast de algemene trend ook seizoensinvloeden bevatten. Ook hier kan het interessant zijn om bepaalde categorische variabelen met elkaar te vergelijken. Bijvoorbeeld het aantal hypotheekaanvragen per gezinssamenstelling over een bepaalde periode.
What’s next?
Naast beschrijvende statistiek kan je voor exploratieve data analyse gebruik maken van statistische methoden. Dit artikel ga ik verder uitbreiden met o.a.:
- Het onderzoeken van de samenhang tussen variabelen met o.a. Anova, Manova, Correlatie (matrix-), Factor analyse en Chi-Squared test.
- Het vaststellen van bepaalde groeperingen in de data met cluster analyse.
- Boruta algoritme voor feature selectie. Features zijn de variabelen met de meeste relevantie, voorspellende kracht, gegeven de gewenste uitkomst.
- Methoden om het aantal kolommen te reduceren, zoals Principle Component Analyse (PCA, reductie van dimensionaliteit).
Ben je geïnteresseerd in voorbeelden van deze statistische methoden voor data analyse in R? Of juist voorbeelden van data visualisaties in R?
Kom dan de komende maanden af en toe terug.
Na het uitbreiden van dit artikel ga ik de voorbeelden verder uitwerken in aparte blog artikelen.
Tot ziens!